


An important feature we see often is processing streams of data, as fast as the data is being generated and scaling quickly to meet the demand of large volumes of events. Downstream services receive the stream and apply business logic to transform, analyze or distribute the data.
Common examples are capturing user behavior like clickstreams and UI interactions. Data for analytics. Data from IoT sensors, etc.
“A continuous stream processor that captures large volumes of events or data, and distributes them to different services or data stores as fast as they come.”
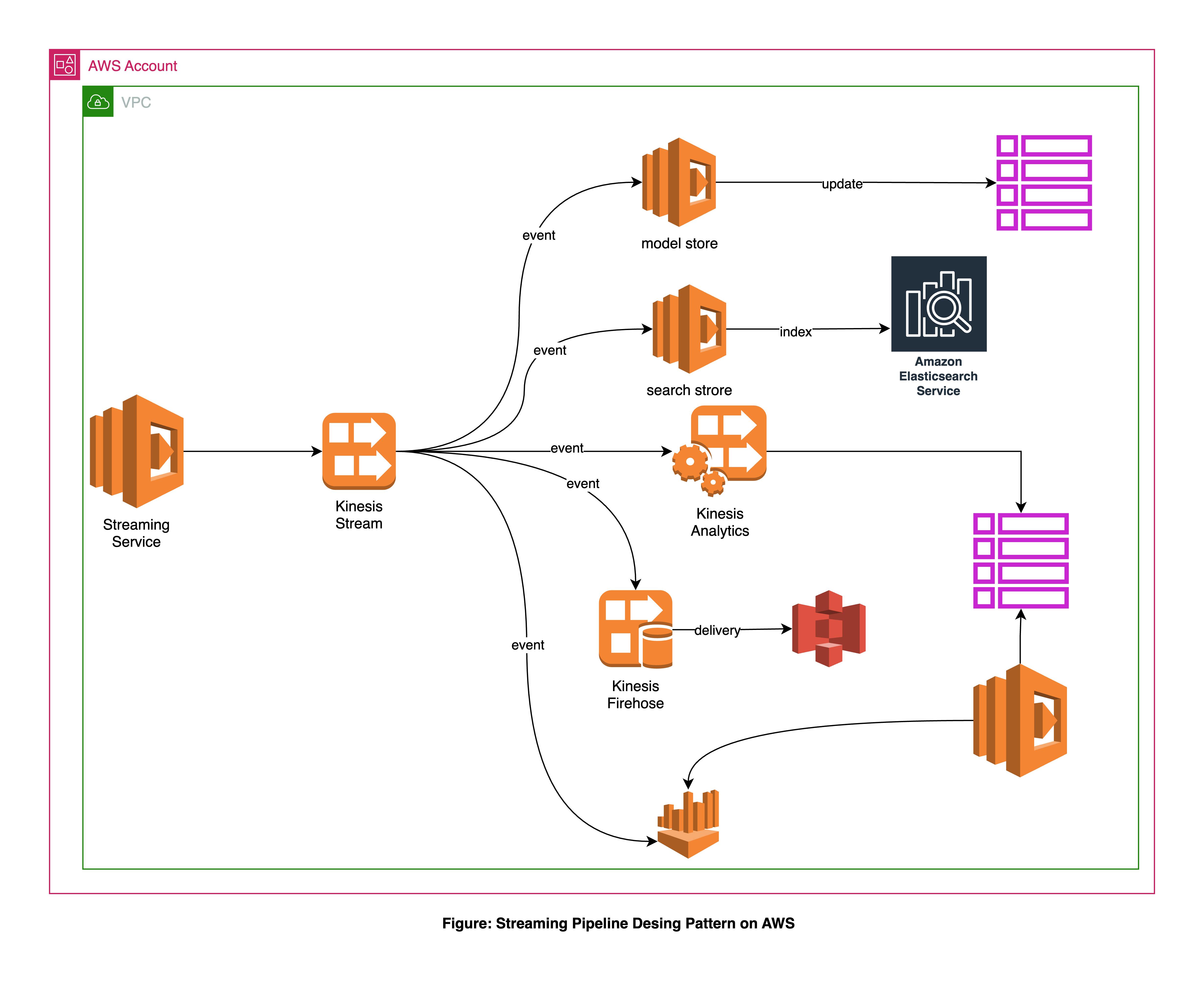
In the example, a Kinesis Stream receives events from Service A. The data is transformed with lambda functions, stored in DynamoDB for fast reading, and indexed in Elasticsearch for a good search user experience.
Kinesis Analytics provides fast querying data in the stream in real-time. With the S3 integration, all the data is stored for future analysis and real insight. Athena provides querying for all the historical data.
Stream processing can be expensive, it might not be worth it if there dataset is small or there are only a few events. All cloud providers have offerings for Data pipelines, Stream processing, and Analytics but they might not integrate well with services that are not part of their ecosystem.